분산 컴퓨팅(distributed computing)에서 대용량 데이터를
병렬 처리(
parallel processing)하기 위해 개발된 소프트웨어
프레임워크(
framework) 또는 프로그래밍 모델.
맵리듀스(
MapReduce)는 구글이 수집한 문서와 로그 등 방대한 데이터들을 분석하기 위해 2004년에 발표한 소프트웨어
프레임워크다.
맵리듀스는 방대한 입력 데이터를 분할하여 여러 머신들이
분산 처리하는 맵(
Map) 함수 단계와 이를 다시 하나의 결과로 합치는 리듀스(Reduce) 함수 단계로 나뉜다.
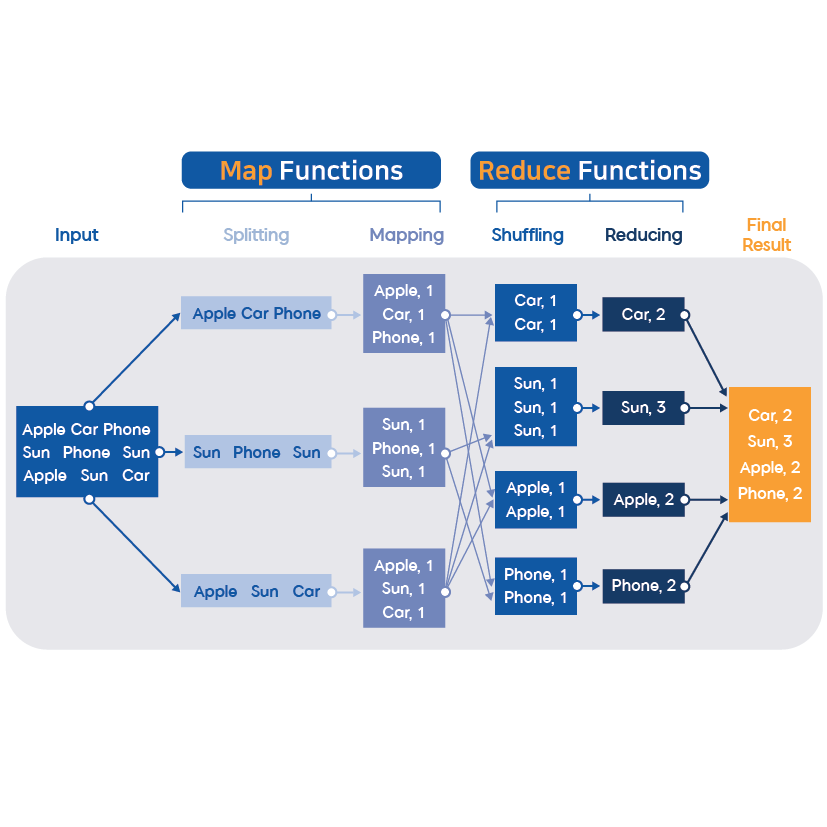
다음은 맵리듀스를 이용한 단어 수 세기(word count) 처리 과정 예시다.
1. 입력(input): 파일을 입력한다.
2. 분할(splitting): 입력한 파일 값을 라인 단위로 분할한다.
3. 매핑(mapping): 분할된 라인 단위 문장을 맵(
Map) 함수로 전달하고, 맵(
Map) 함수는 공백을 기준으로 문자를 분리하여 단어 개수를 확인한다.
4. 셔플링(shuffling): 메모리에 저장된 맵(
Map) 함수의 출력 데이터를 분배(partitioning) 및 정렬하여 로컬 디스크에 저장하고, 네트워크를 통해 리듀스(Reduce) 함수의 입력 데이터로 전달한다.
5. 리듀싱(reducing): 단어 목록들을 반복적으로 수행하고 합을 계산하여 표시한다.
맵리듀스는 단순해서 사용이 편리하고 확장이 쉽다. 특정
데이터 모델이나 스키마, 질의 언어에 의존적이지 않아
비정형 데이터(unstructured data) 분석에 용이하다. 그러나 복잡한 연산 처리가 쉽지 않고 기존의
데이터베이스 관리 시스템(
DBMS)이 제공하는 스키마, 질의 언어, 인덱스 등의 기능을 지원하지 않는다. 또한 맵(
Map) 단계가 끝나야 리듀스(Reduce) 단계를 시작할 수 있어서
관계형 데이터베이스(
RDB)에 비해 상대적으로 성능이 떨어진다.
반면 저장 구조가 독립적이라 데이터 복제 시 데이터 내구성(데이터를 손실로부터 보호하는 특성)이 좋다.