유니코드 문자를 기존 문자 체계와의 상호 호환을 위해 가변 길이의 바이트열 값으로 인코딩하는 방식.
유니코드(Unicode)는 전 세계의 거의 모든 문자에 고유 숫자를 부여한 문자 집합으로, 1993년 국제 표준(ISO/IEC 10646)으로 제정되었다. 유니코드는 기본적으로 2 바이트로 한 문자를 표현하여, 기존 7 비트 또는 8 비트로 한 문자를 표현하는 아스키(ASCII) 문자 기반 시스템과 호환을 위해 UTF를 사용한다. UTF 인코딩 방식으로 UTF-8, UTF-16 및 UTF-32 등이 있다. UTF 뒤의 숫자는 한 문자를 인코딩하는 길이로, UTF-8은 유니코드 문자를 8비트(1바이트) 값으로 인코딩함을 의미한다. 대표적인 UTF 인코딩 방식은 다음과 같다.
▷ UTF-8: 모든 유니코드 문자(코드포인트)를 1 ~ 4 바이트의 8 비트 단위로 인코딩한다. 유니코드 문자 모두를 인코딩하며 가장 많이 사용되는 방식이다. 표준 영어 및 기호는 1 바이트(7비트 ASCII와 동일), 추가 라틴 및 중동 문자는 2 바이트, 한글을 포함한 아시아 문자는 3 바이트, 그리고 추가 문자는 4 바이트를 사용하여 표현한다. 웹에서 많이 사용되며,
W3C는
XML 및
HTML의 기본 인코딩으로 UTF-8을 권장한다.
▷ UTF-16: 2 바이트(16 비트) 단위로 1~ 2개를 사용하여 유니코드의 유효한 모든 문자를 인코딩할 수 있다.
기본 다국어 평면
(BMP:
Basic Multilingual Plane)에 속하는 문자들은 그대로 16 비트 값으로 인코딩하고, 추가 문자는 32 비트(16비트 2개) 값으로 인코딩한다. 자바(Java) 프로그래밍에서 기본으로 사용된다.
▷ UTF-32: 유니코드 문자를 모두 4 바이트(32 비트)
고정 길이로 인코딩한다. 유니코드의 모든 문자에 해당하는 UTF-32 값이 색인화되어 있어, 인코딩 변환 처리가 따로 필요 없다. 그러나 모든 문자가 4 바이트를 차지하는 메모리상의 비효율로 다른 UTF-8과 UTF-16에 비해 많이 사용되지 않는다.
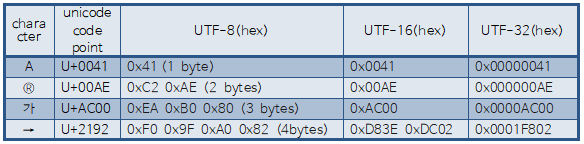
예를 들어, 알파벳 대문자 ‘A’의 유니코드 값(코드포인트※)은 'U+0041'로, UTF-8로 변환하면 0x41(이진수 01000001), UTF-16으로 변환하면 0x0041, UTF-32로 변환하면 0x00000041(십진수 65)이다. 한글 ‘가’의 유니코드 값은 ‘U+AC00'이다. 이를 UTF-8로 변환하면, 0xEA 0xB0 0x80(이진수 11101010:10110000:10000000), UTF-16으로 변환하면 0xAC00, UTF-32로 변환하면 0x0000AC00(십진수 44,032)이다.
※ 유니코드에서 각 문자에 부여하는 고유 숫자 값(예: U+0041)을 코드 포인트(code point)라 한다.