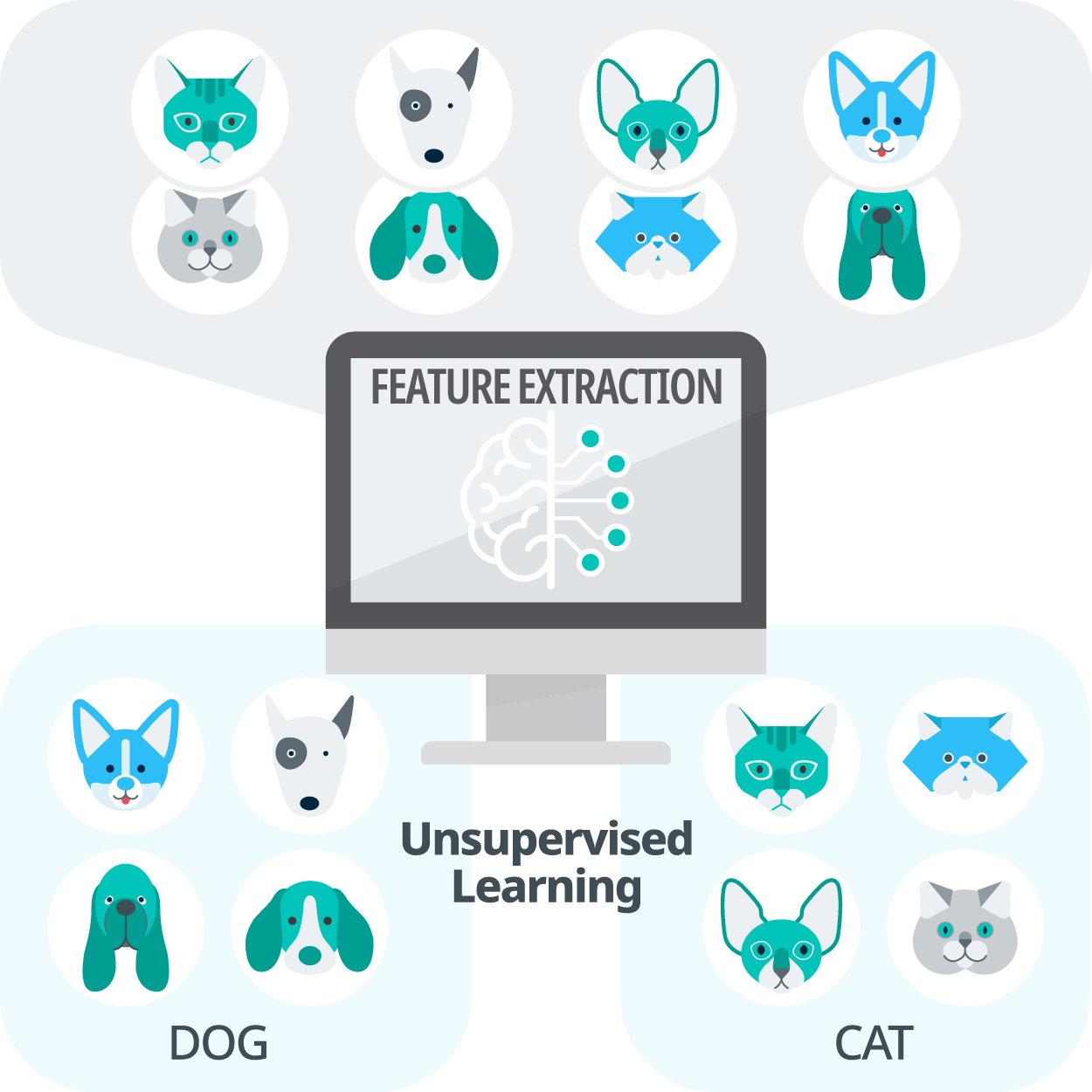
기계 학습 중 컴퓨터가 입력값만 있는 훈련 데이터를 이용하여 입력들의 규칙성을 찾는 학습 방법. 비지도형 학습 모델은 사람의 해석을 통해 유용한 지식을 추출하는 데 활용되거나 지도형 기계 학습(supervised learning)에서의 원래 입력보다 데이터 특징을 더 잘 표현하는 새로운 입력을 만드는 특징 추출기(feature extractor)로 활용된다.
학습 훈련 데이터(training data)로 출력 없이 입력만 제공되는 상황을 문제(입력)의 답(출력)을 가르쳐 주지 않는 것에 비유해 비지도형 기계 학습(이하 ‘비지도 학습’)이라고 한다. 입력의 규칙성에 따라 군집 분석(Cluster analysis), 의존 구조(dependencystructure) 학습, 벡터 양자화(vector quantization), 데이터 차원 축소(data dimensionality reduction) 등으로 구분한다. 군집 분석과 의존 구조 학습은 주로 데이터에 내재하는 유용한 정보나 지식을 추출하는 데 활용된다. 예를 들어, 유전자 데이터에서 학습된 유전자 사이의 의존 구조는 생의학 연구자들에게 새로운 지식을 제공할 수 있다. 벡터 양자화와 데이터 차원 축소는 데이터의 잡음과 불필요한 입력을 제거하며, 지식 추출, 데이터 압축 및 특징 추출(feature extraction) 등에 적용된다. 특징 추출은 원래 입력보다 데이터를 더 잘 표현하는 새로운 입력을 만드는 것을 의미하며, 추출된 특징은 지도 학습의 성능을 향상시키는 데 이용된다. 비지도 학습을 위한 군집 분석 방법에는 k-평균 군집화 및 계층적 군집화 등이 있고, 의존 구조 학습의 대표적 방법에는 베이즈 망(Bayesian network)이 있다. 벡터 양자화의 대표적 방법에는 린데·부조·그레이(Linde-Buzo-Gray) 알고리즘이 있으며, 데이터 차원 축소 방법에는 선형 방법인 주성분 분석(principal components analysis)과 인공 신경망 기반 비선형 방법인 오토인코더(autoencoder) 등이 있다.
※ 의존 구조 학습: 데이터의 변수들 사이의 확률적 독립(independence)과 의존(dependence) 관계를 표현하는 그래프 구조를 학습하는 것. 확률적 독립과 의존은 인과 관계(causal relation)와 깊은 관련이 있기 때문에 변수들 사이의 인과 관계를 분석하는데 유용하다. ※ 벡터 양자화: 주어진 데이터를 적은 수의 원형(prototype) 벡터를 이용하여 근사(approximation)하는(똑같지는 않지만 비슷한 값을 가지도록 간략하게 나타내는) 것. ※ 데이터 차원 축소: 주어진 데이터를 원래 변수의 개수보다 적은 수의 변수를 이용하여 근사하는 것. 원래 데이터에 존재하는 정보를 최대한 보존하면서 변수의 개수를 줄이는 것이 목적이다. ※ k-평균 군집화: 데이터를 k 개의 부분 집합(군집)으로 나누는 것으로, k는 사람이 정함 ※ 계층적 군집화: 데이터를 계층적으로 분할하거나 병합하는 군집 분석 ※ 베이즈 망: 확률적 의존관계(probabilistic dependency)를 그래프로 표현하는 모델 ※ 린데·부조·그레이 알고리즘: 코드북 생성에 사용되는 벡터 양자화 알고리즘으로, k-평균 군집화 알고리즘과 유사하다(Y. Linde, A. Buzo. and R. M. Gray, 1980) ※ 주성분 분석: 데이터 왜곡을 최소화하는 저차원 표현을 학습하는 것 ※ 오토인코더: 입력을 재구성(reconstruction)하는 신경망 모델