네트워크를 통해 물리적으로 다른 위치에 있는 여러 컴퓨터에 자료를 분산 저장하여 마치 로컬 시스템(local system)에서 사용하는 것처럼 동작하게 하는 시스템.
분산 파일 시스템(
DFS:
Distributed File System)에서는 다수의 사용자가 원격으로 데이터를 쉽게 공유할 수 있도록 한다. 이렇게 하여 데이터의 가용성(
data availability)을 향상하고, 데이터를 물리적으로 다른 위치에 중복하여 저장함으로써 디스크에 장애가 발생하더라도 단일 서버 환경에서보다 상대적으로 쉽게 복구할 수 있다. 그러나 네트워크를 사용하기 때문에 시스템 노드(node)들 간 연결을 보호해야 하며, 노드(node)들 간에 데이터를 전송할 때 데이터가 손실되거나 누락될 가능성이 있다. 또한 여러 클라이언트 노드(node)에서 동시에 동일 데이터로 접근하거나 전송을 요청할 경우 지연 및 장애가 발생할 수 있다.
대표적인 분산 파일 시스템들은 다음과 같다.
- 구글 파일 시스템(
GFS: Google
File System): 구글(Google)이 자사의 핵심
데이터 저장소와 검색 엔진을 위해 개발한 분산 파일 시스템. 하드웨어의 안정성과 자료의 유실문제 처리, 높은 데이터 처리율이 특징이다.
-
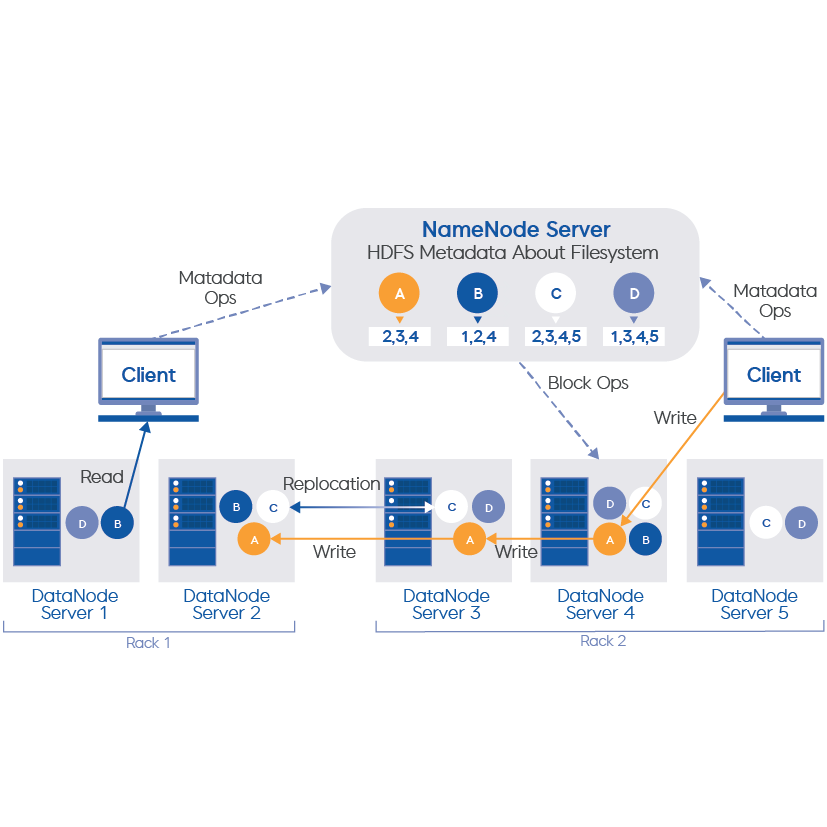
하둡 분산 파일 시스템(HDFS:
Hadoop Distributed File System):
GFS를 모델로 만든
오픈소스 분산 파일 시스템.
GFS와 동일한 특징을 가진다. 대용량의 파일을 블록 단위로 분할하여 데이터 노드(DataNode)에 저장하며, 블록이 어느 데이터 노드에 저장되었는지에 대한
메타데이터(
metadata)를 네임노드(NameNode)에 저장하는 구조다.
* 블록: 블록은 청크라고도 하며, 기본
설정값은 64MB이다.
- 앤드루
파일 시스템(
AFS:
Andrew File System): 카네기 멜론 대학교에서 개발한 분산 파일 시스템. 캐시를 사용하여 성능 향상을 하고 파일 복제로 가용성, 안정성, 확장성을 제공한다.
- 글러스터FS(GlusterFS): 다수의 스토리지를
스케일 아웃(
scale out) 방식인
병렬 네트워크 파일 시스템으로 통합하여 제공하는
소프트웨어 정의 스토리지(
SDS:
Software Defined Storage)형 분산 파일 시스템.